
Мы часто пишем о новых видеокодеках, таких как AV1 или H.266, а недавно мы рассмотрели формат изображения AVIF, который предлагает улучшенный коэффициент качества/сжатия по сравнению с WebP и JPEG. Но в данном обзоре расскажем о аудиокодеках.
Когда в 2017 году был выпущен Opus 1.2, он предлагал достойное качество речи с битрейтом всего 12 кбит/с, выпуск Opus 1.3 в 2019 году улучшил кодек с высококачественной речью, возможной всего на 9 кбит/с. Но, недавно Google AI представил кодек Lyra с очень низким битрейтом для сжатия речи, который обеспечивает высокое качество речи с битрейтом всего 3 кбит/с.
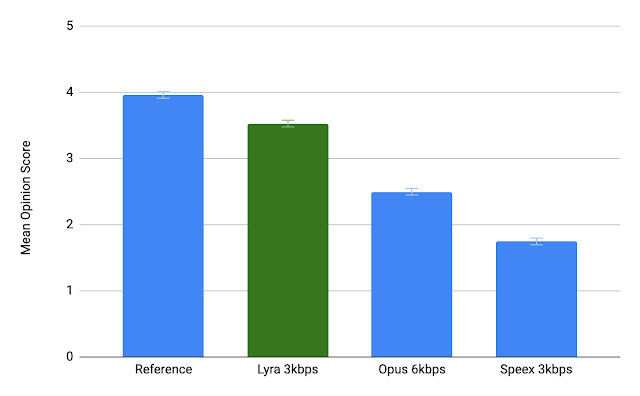
Прежде чем мы углубимся в детали кодека Lyra, Google сравнил эталонный аудиофайл, закодированный с помощью Lyra со скоростью 3 кбит/с, Opus со скоростью 6 кбит/с (минимальный битрейт для Opus) и Speex со скоростью 3 кбит/с, и пользователи сообщили, что Lyra звучит лучше всего, и близко к оригиналу. Вы действительно можете попробовать это сами.
Чистая Речь
Оригинал
Opus со скоростью 6 кбит/с
Lyra со скоростью 3 кбит/с
Speex со скоростью 3 кбит/с
Шумная Обстановка
Оригинал
Opus со скоростью 6 кбит/с
Lyra со скоростью 3 кбит/с
Speex со скоростью 3 кбит/с
Из всех образцов хуже всех звучит Speex 3kbps. Как нам кажется Opus 6kbps и Lyra 3kbps звучат примерно одинаково с образцами чистой речи, но Lyra лучше воспроизводит фоновую музыку в шумной среде.
Так как же работает Lyra? Google AI объясняет, что базовая архитектура кодека Lyra основана на функциях (спектрограммы log mel) или отличительных речевых атрибутах, представляющих энергию речи в разных частотных диапазонах, извлекаемых из речи каждые 40 мс и затем сжимаемых для передачи. На принимающей стороне генеративная модель использует эти функции для воссоздания речевого сигнала.
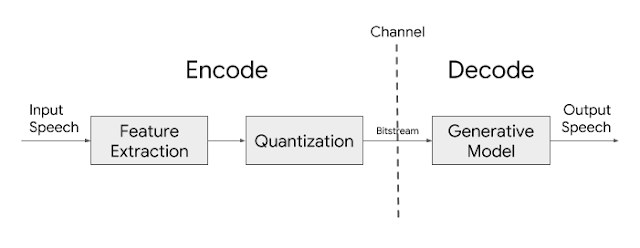
Lyra работает аналогично стандарту кодирования речи с линейным предсказанием со смешанным возбуждением (MELP), разработанному Министерством обороны США (US DoD) для военных приложений и спутниковой связи, защищенного голоса и защищенных радиоустройств.
Lyra также использует генеративные модели с естественным звуком, чтобы поддерживать низкий битрейт при достижении высокого качества, аналогичного тому, которое достигается кодеками с более высоким битрейтом.
Используя эти модели в качестве основы, мы разработали новую модель, способную реконструировать речь с использованием минимальных объемов данных. Lyra использует мощь этих новых генеративных моделей естественного звучания для поддержания низкого битрейта параметрических кодеков при одновременном достижении высокого качества, наравне с современными кодек-формами сигналов, используемыми сегодня в большинстве потоковых и коммуникационных платформ. Недостатком кодеков waveform является то, что они достигают такого высокого качества путем сжатия и передачи сигнала по выборке за выборкой, что требует более высокого битрейта и в большинстве случаев не является необходимым для достижения естественного звучания речи.
Одна из проблем генеративных моделей — их вычислительная сложность. Lyra избегает этой проблемы, используя более дешевую рекуррентную генеративную модель, вариант WaveRNN, который работает с более низкой скоростью, но генерирует параллельно несколько сигналов в разных частотных диапазонах, которые позже объединяются в один выходной сигнал с желаемой частотой дискретизации. Этот трюк позволяет Lyra работать не только на облачных серверах, но и на устройствах среднего класса в реальном времени (с задержкой обработки 90 мс, что соответствует другим традиционным речевым кодекам). Затем эта генеративная модель обучается на тысячах часов речевых данных и оптимизируется, подобно WaveNet, для точного воссоздания входного звука.
Lyra обеспечит разборчивую высококачественную голосовую связь даже с сигналами низкого качества, низкой пропускной способностью и/или перегруженными сетевыми соединениями. Это работает не только для английского языка, так как Google обучил модель тысячам часов аудио с говорящими на более чем 70 языках с использованием аудиобиблиотек с открытым исходным кодом, а затем проверил качество звука с помощью опытных и привлеченных слушателей.
Компания также ожидает, что видеозвонки станут возможны через модемное соединение со скоростью 56 кбит/с благодаря комбинации видеокодека AV1 с аудиокодеком Lyra. Одним из первых приложений, использующих аудиокодек Lyra, будет приложение для видеозвонков Google Duo, которое будет использоваться в соединениях с очень низкой пропускной способностью. Компания также планирует работать над ускорением с использованием графических процессоров и ускорителей искусственного интеллекта и начала исследовать, можно ли использовать технологии, используемые для Lyra, для создания универсального аудиокодека для музыки и неречевого звука. Более подробную информацию можно найти в сообщении блога Google AI.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту cnx-software.com.
Оригинал статьи вы можете прочитать здесь.