
На прошлой неделе мы писали о карте Hailo-8 M.2, обеспечивающей до 26 TOPS производительности AI и сравнивающейся с Google Edge TPU и Intel Movidius Myriad X как с точки зрения занимаемой площади, так и производительности и эффективности.
С тех пор у нас была конференц-связь с Лиран Бар, вице-президентом по развитию бизнеса Hailo, где у нас было время обсудить больше о решениях Hailo AI, а также о том, как интерпретировать и понимать тесты AI, которые во многих случаях могут вводить в заблуждение.
Архитектура Hailo-8

В первом обзоре мы отметили, что чипу удалось получить дополнительную производительность и эффективность благодаря «запатентованной новой архитектуре потока данных, управляемой структурой, вместо обычной архитектуры фон Неймана». Но это звучит абстрактно, поэтому Лиран сказал нам, что одна из ключевых причин повышения производительности заключается в том, что оперативная память является автономной без необходимости во внешней DRAM, как в других решениях. Это значительно снижает задержку и снижает энергопотребление.
Внутри чип Hailo-8 состоит из трех типов блоков — управления, памяти и вычислений, которые назначаются различным уровням нейронной сети, как показано на анимации ниже.
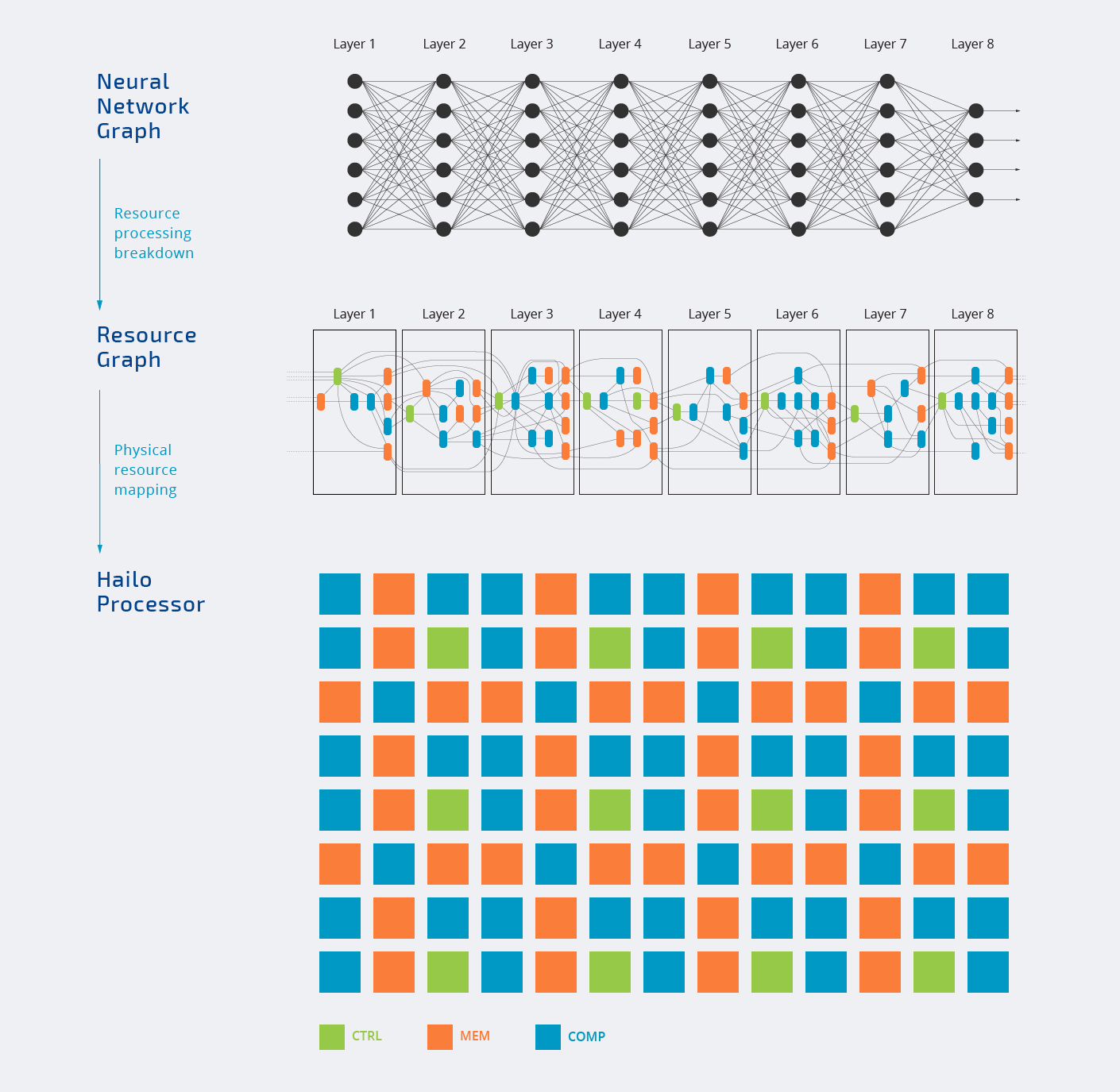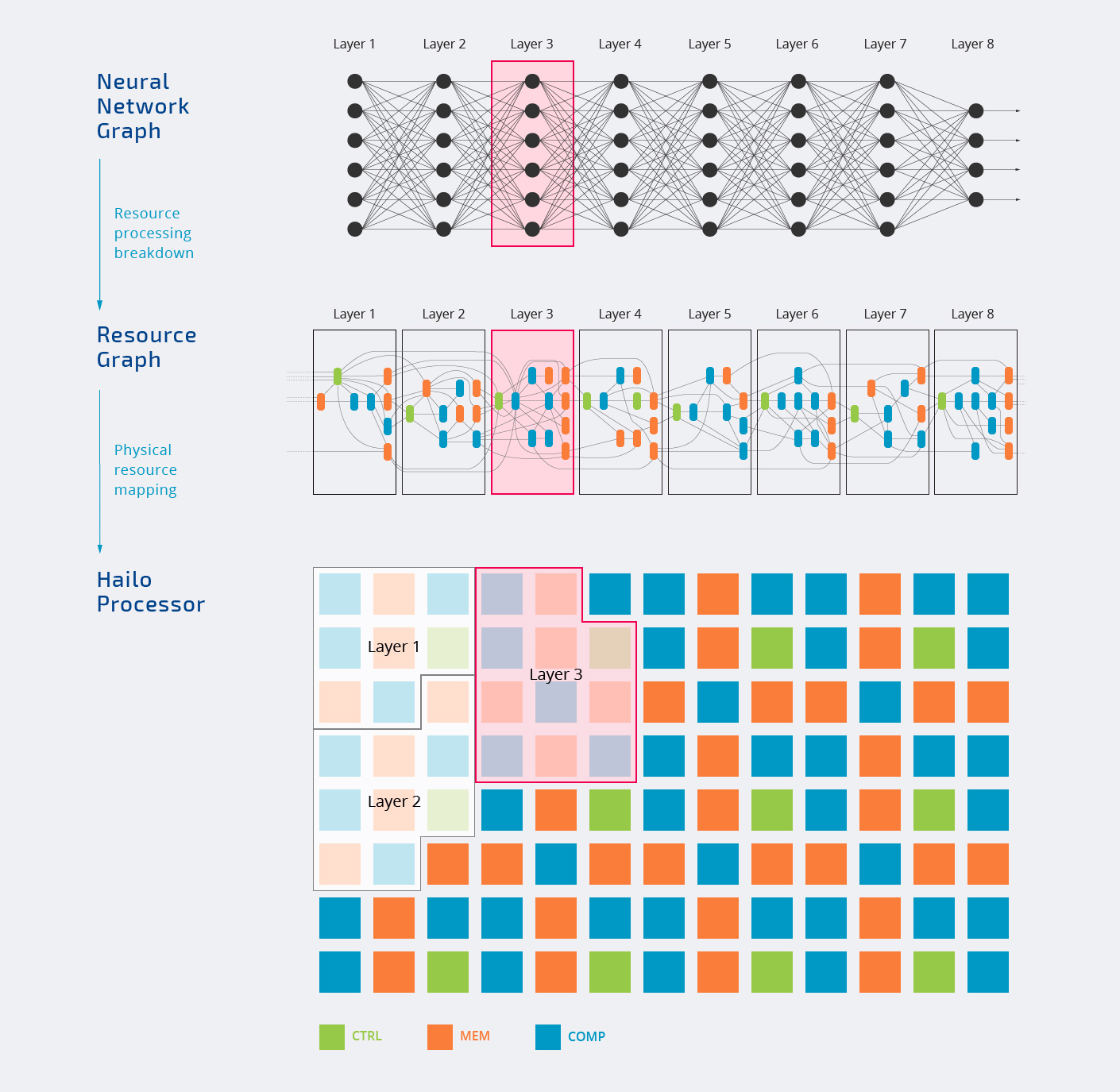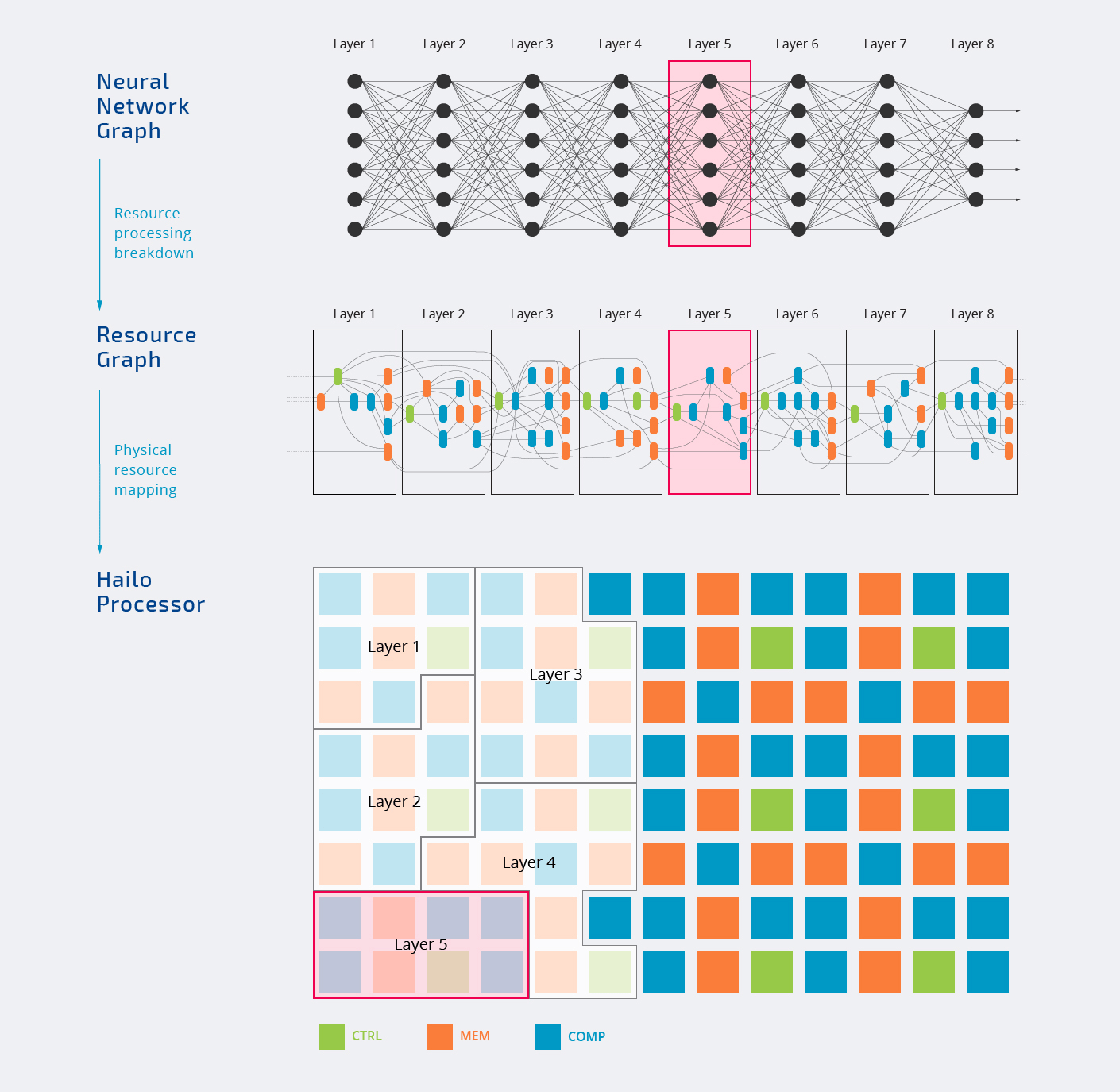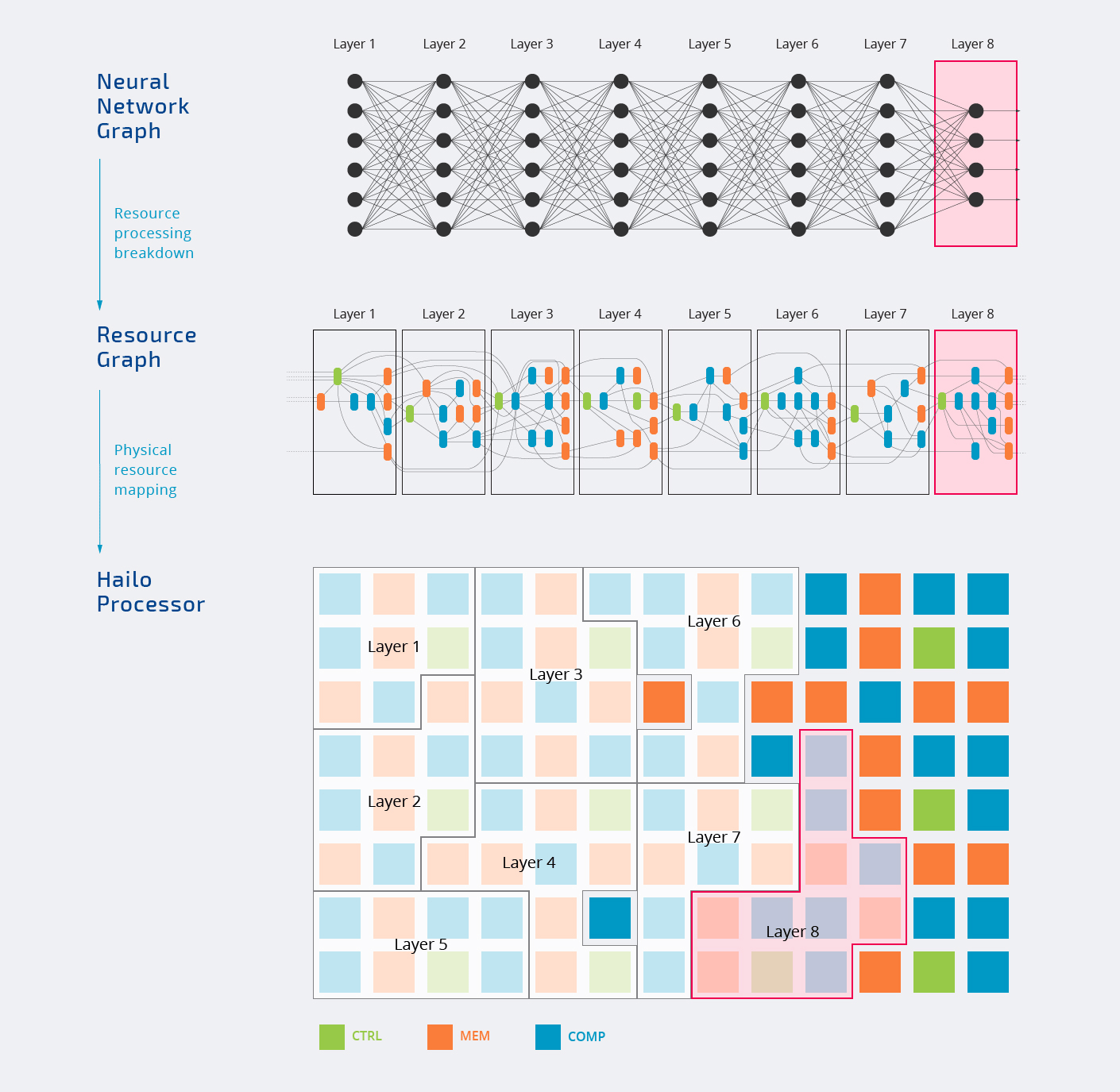
Вся обработка происходит внутри чипа. Вы также заметите, что не все блоки назначены, и это нормально, поскольку каждая рабочая нагрузка ИИ будет использовать только части ускорителя ИИ. Вот почему часто топовое число, рекламируемое компаниями, преимущественно является “маркетинговым ходом”.
Верхняя диаграмма также показывает, что Hailo-8 может использоваться как в автономном режиме, так и в качестве сопроцессора. Большинство компаний будут стыковать чип с более мощным хост-процессором для решения других задач, но в теории, также возможно использовать Hailo-8 сам по себе.
Инструменты Разработки Hailo-8

Компания предоставляет оценочную плату Hailo-8 с разъемами PCIe, Gigabit Ethernet, аудио, портами USB, интерфейсами I2C и UART, GPIO, а также двумя интерфейсами камеры MIPI CSI. Устройство предназначено для подключения к компьютеру, на котором вы можете использовать инструменты разработки для обучения TensorFlow или ONNX, прежде чем получить модель через Hailo SDK для преобразования данных и распределения ресурсов, как показано на анимации Hailo-8, представленной выше.
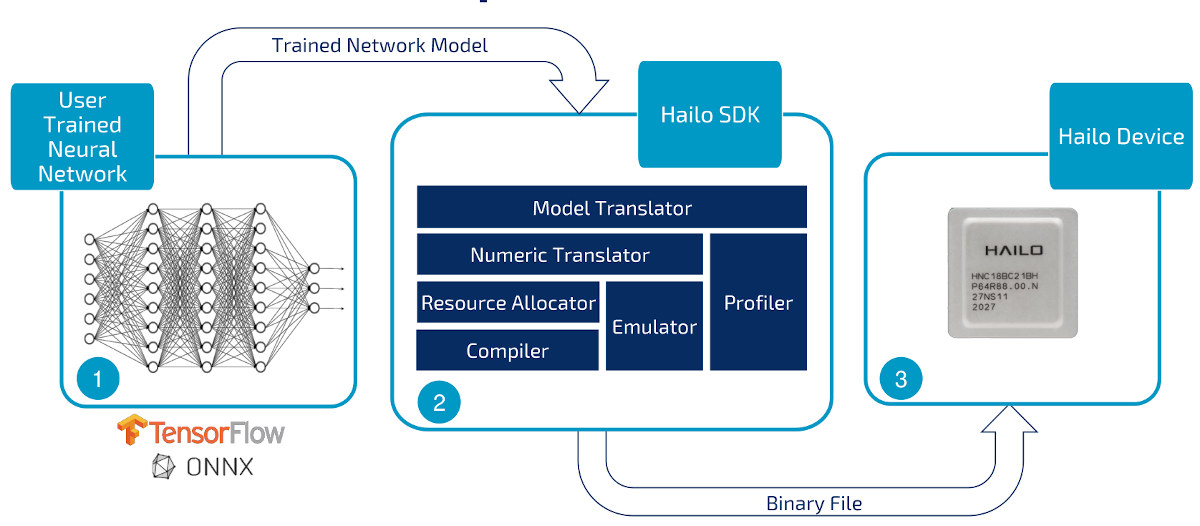
Если вы хотите получить инструменты для разработки аппаратного и программного обеспечения, вам необходимо предоставить сведения о компании и проекте. Мы спросили, сделает ли Hailo их более доступными, и нам ответили, что сейчас компания сосредоточена на коммерческих проектах. Hailo — израильский стартап, основанный в 2017 году, и хотя они получили 88 миллионов инвестиций от NEC, ABB и других инвесторов, компания, скорее всего, сейчас не получает никакой прибыли. Поступили также запросы от университетов на Hailo, но им пришлось отклонить их, поскольку они, будучи небольшой компанией, не имеют ресурсов для оказания техподдержки. Если у вас есть проект, вы можете запросить устройство на странице продукта.
Hailo-8 против NVIDIA Jetson

В своем пресс-релизе компания сосредоточилась на сравнении с чипами Edge TPU и Myriad X, но, судя по количеству TOPS, производительность Hailo-8 гораздо ближе к такому решению, как NVIDIA AGX Xavier. Как вы можете видеть на фотографии выше, форм-фактор намного меньше и это может быть существенным для вашего приложения, если вы используете несколько ускорителей искусственного интеллекта в одном приложении. Это не значит, что оба они одинаковы, так как NVIDIA AGX Xavier более гибок, так как вы также можете проводить обучение на платформе, в то время как Hailo-8 предназначен только для маломощного вывода, который он делает с 20-кратной энергоэффективностью.

На приведенной выше диаграмме показана производительность Hailo-8 по сравнению с NVIDIA Jetson Nano, Jetson TX2 и Jetson Xavier NX с использованием Resnet-v1-50, MobileNet-v1-SSD и Yolo-v3 Tiny. В этих трех тестах Hailo-8 немного быстрее, чем Jetson Xavier NX, но будет намного более эффективным, поскольку потребляемая мощность NVIDIA Jetson Xavier NX составляет до 10 или 15 Вт в зависимости от используемого режима.
Вы можете спросить, почему есть примечание о размере батча. Это связано с тем, что Jetson Xavier NX использует как графический процессор NVIDIA Volta, так и механизмы NVDLA, а графические процессоры лучше работают с высокопараллельными задачами, поэтому размер батча настраивается и влияет как на производительность, так и на эффективность.
Расшифровка тестов AI
Компании, занимающиеся микросхемами искусственного интеллекта, любят указывать цифры TOPS, чтобы показать максимальную теоретическую производительность своих микросхем. Но на практике это только для маркетинга. Например, Hailo-8 рекламируется с 26 TOPS, в то время как Google Edge TPU поддерживает до 4 TOPS. Это в шесть раз выше производительности, но при запуске реального теста Hailo в среднем в 13 раз быстрее Edge TPU из-за архитектурных различий. Как мы отмечали выше, никакая рабочая нагрузка AI не будет использовать все ресурсы от чипа до объявленных TOPS.
Поэтому к числам TOPS всегда следует относиться с недоверием, и вы можете вместо этого полагаться на тесты, но и здесь есть подводные камни. Если мы посмотрим на тесты Jetson Xavier AGX, мы увидим, что размер батча четко указан.
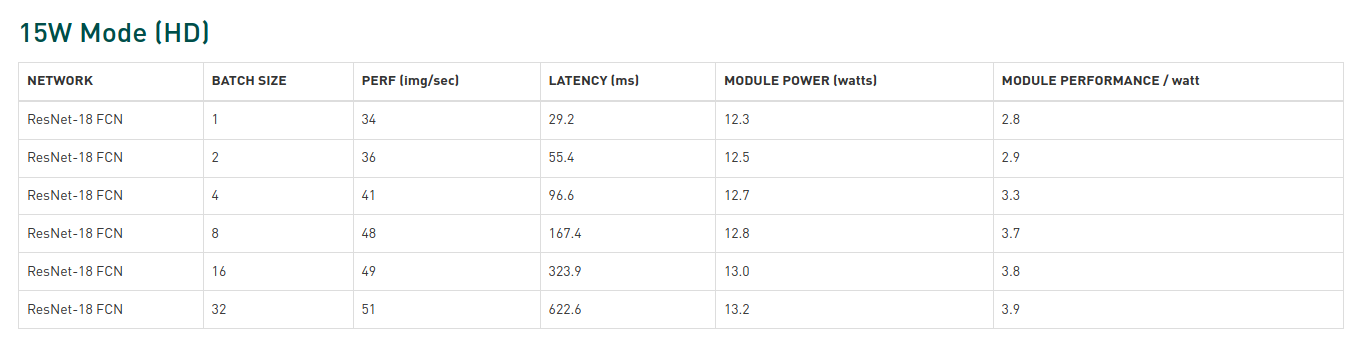
Но когда мы переходим на более поздние платформы Jetson больше нет упоминания о размере батча.
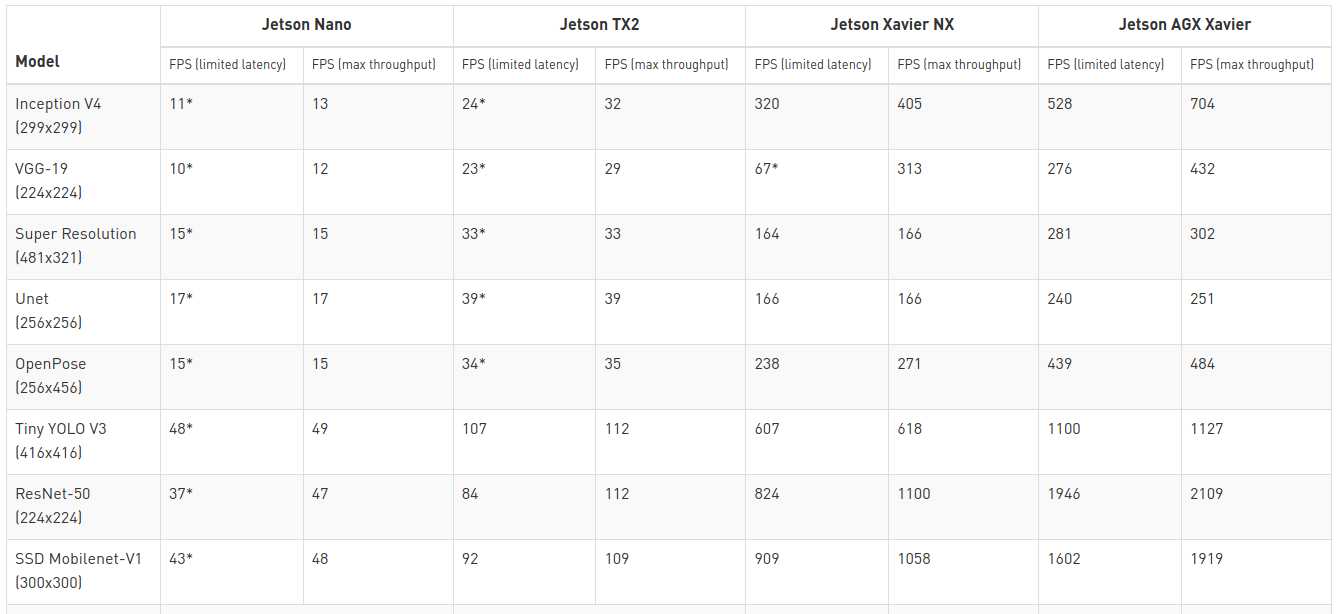
Так что сравнение немного затруднено. NVIDIA, по-прежнему, заявляет, что «результаты минимальной задержки были получены с максимальным размером батча, который не превышал бы задержку 15 мс (50 мс для BERT) — в противном случае использовался размер батча, равный единице». Это правда, за исключением результата, отмеченного *, где задержка превышает 15 мс.
Стандартные тесты все еще могут помочь, но нужно быть внимательным к деталям. SSD-накопитель MobileNet-v1 обычно работает с размером изображения 300 × 300, но Google решил запустить тест с меньшими изображениями 224 × 224 на Edge TPU.
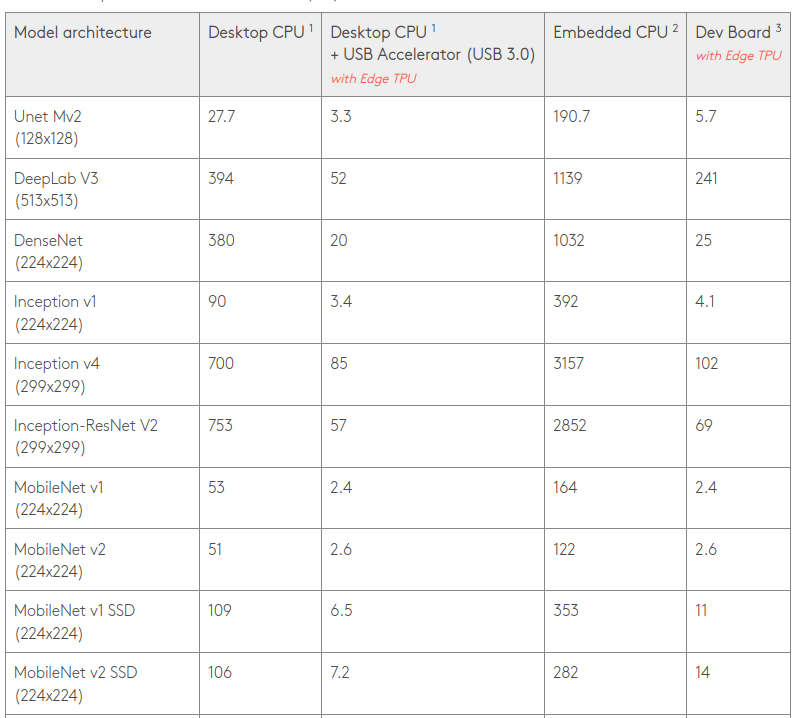
Компания также показывает результаты для настольных процессоров с USB-ускорителем и без него, и то же самое для встроенного процессора. Последний представляет собой процессор с четырьмя ядрами Cortex-A53, а «настольный процессор» — это 18-ядерный/36-поточный процессор Intel Xeon Gold 6154 за ~ 4000 долларов с TDP 200 Вт. Поэтому, когда вы видите тесты, показывающие TOPS на ватт для ускорителя, это становится гораздо менее актуальным при подключении к процессору 200 Вт …

Google пишет: «Отдельный Edge TPU способен выполнять 4 триллиона операций (тераопераций) в секунду (TOPS), используя 0,5 Вт на каждый TOPS (2 TOPS на ватт)». Но, основываясь на описанных выше тестовых приемах и других расчетах, Hailo оспаривает утверждения Google о 2 TOPS/Вт и вместо этого заявляет об эффективности всего 0,3 TOPS/Вт, что делает Hailo-8 в десять раз более энергоэффективным!
Лучше никому не верить, если возможно, получить оценочную плату для каждой целевой платформы и запускать свои собственные рабочие нагрузки ИИ.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту cnx-software.com.
Оригинал статьи вы можете прочитать здесь.