
Компания Deci представила созданные AutoNAC модели «DeciNets» для процессоров Intel Cascade Lake, которые, как утверждается, намного быстрее и точнее, чем другие модели классификации изображений для процессоров. Между тем, Aaeon объявила, что на ее платах UP доступен NPU Hailo-8.
В июле прошлого года Deci объявила о своем семействе предварительно обученных моделей классификации изображений DeciNets, которые создаются на основе запатентованной израильской компанией технологии Automated Neural Architecture Construction (AutoNAC). Сегодня представители Deci сообщили, что предварительно обученные сети DeciNet теперь доступны для процессоров Intel Cascade Lake, таких как масштабируемые процессоры Xeon 2-го поколения. Сети DeciNet, работающие на Intel Cascade Lake, «обеспечивают более чем двукратное увеличение времени выполнения в сочетании с повышенной точностью по сравнению с самыми мощными общедоступными моделями, такими как EfficientNets, разработанными Google», — утверждает Deci.
Что касается других новостей, связанных с искусственным интеллектом, Aaeon объявила, что делает карту ускорителя Hailo Hailo-8 M.2 с производительностью до 26 TOPS, доступную для SBC UP Squared Pro, UP Squared 6000 и UP Xtreme i11 (см. Ниже).
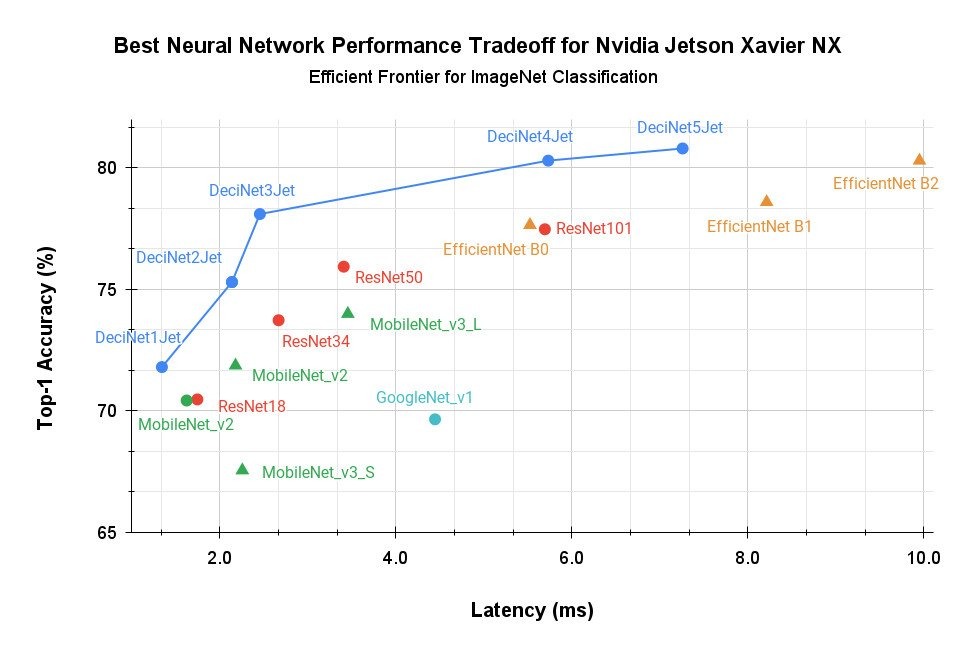
DeciNets может работать на любом типе основных процессоров, включая GPU и FPGA. Эта технология уже оптимизирована для графических процессоров Nvidia Jetson Xavier NX для периферийного искусственного интеллекта (см. диаграмму выше), а также для графических процессоров Nvidia T4 для облака.
Благодаря сотрудничеству с Intel и поддержке Cascade Lake компания Deci сосредоточилась на относительно неиспользованной маркировке для классификации изображений на процессорах. Процессоры, как правило, дешевле и более распространены, чем графические процессоры. Они также выполняют множество задач по сравнению с графическими процессорами, которые часто используются для безголовых задач, в которых графический процессор используется только для ИИ. Тем не менее, графические процессоры продолжают доминировать в ИИ, поскольку модели глубокого обучения обычно работают в 3-10 раз медленнее на ЦП, чем на графическом процессоре, говорит представитель компании Deci.
По словам Deci, DeciNets «значительно сокращает разрыв между производительностью GPU и CPU для CNN», позволяя выполнять задачи, выполняемые на ЦП, поскольку ранее они были слишком ресурсоемкими. С DeciNets «разрыв между производительностью логического вывода модели на графическом процессоре и центральным процессором сокращается вдвое без ущерба для точности модели».
Глубокое обучение можно ускорить на многих уровнях, начиная с инструкций внутри процессоров, таких как инструкции Deep Learning Boost, встроенные в процессоры Cascade Lake, Tiger Lake и Alder Lake. Другие решения включают надстройки аппаратного ускорителя, такие как Hailo-8, Myriad X от Intel или NPU Edge TPU от Google. Среды выполнения и компиляторы, такие как Tensor RT от Nvidia или OpenVino от Intel, которые встроены в AutoNAC от Deci, также играют роль, но одним из наиболее важных факторов является модель глубокого обучения сверточной нейронной сети (CNN).
AutoNAC
Производительность модели глубокого обучения связана с нейронной архитектурой, которая использовалась для ее разработки. AutoNAC от Deci, который конкурирует с аналогичными технологиями, такими как технология Google Neural Architecture Search (NAS), представляет собой технологию алгоритмического ускорения, которая зависит от аппаратного обеспечения и работает поверх других методов оптимизации.
AutoNAC содержит компонент NAS, который пересматривает заданную обученную модель, чтобы «оптимально ускорить ее выполнение в 15 раз, сохраняя при этом базовую точность модели», — говорит Deci. Intel ранее использовала AutoNAC для ускорения скорости логического вывода нейронных сетей ResNet50, работающих на процессорах Intel, «сокращая задержку представленных моделей до 11,8 раз и увеличивая пропускную способность до 11 раз», — говорит Deci.
Процесс оптимизации AutoNAC позволяет оптимизировать каждую из сетей DeciNet для целевого оборудования логического вывода конкретного приложения. Этот процесс требует довольно продолжительного предварительного обучения с участием клиента, с использованием инструментов развертывания Deci Infery и RTiC. Тем не менее, как отмечается в истории ZDNet на DeciNets, которая включает интервью с Йонатаном Гейфманом, соучредителем и генеральным директором Deci, дополнительное обучение приводит к снижению эксплуатационных расходов и задержек, а также к повышению производительности.
Можно модифицировать несколько сетей DeciNet, чтобы предложить различные компромиссы между задержкой и стоимостью эксплуатации. Хотя первоначальный акцент проекта DeciNets Cascade Lake был сделан на центр обработки данных, аппаратно-ориентированный подход к технологии также должен помочь получить максимальную отдачу от ограниченного периферийного оборудования ИИ, говорится в статье.
«Как специалисты по глубокому обучению, наша цель состоит не только в том, чтобы найти наиболее точные модели, но и в том, чтобы раскрыть наиболее ресурсоэффективные модели, которые без проблем работают в производственной среде — это сочетание эффективности и точности представляет собой «святой Грааль» глубокого обучения». заявил генеральный директор Deci Гейфман. «AutoNAC создает лучшие на сегодняшний день модели компьютерного зрения, и теперь новый класс сетей DeciNet можно применять и эффективно запускать приложения ИИ на процессорах».
Hailo-8 теперь доступен на платах UP
Aaeon предлагает свои собственные модули mini-PCIe и M.2, оснащенные ускорителями глубокого обучения Intel Movidius Myriad X, для поддерживаемых сообществом плат Intel «UP Bridge the Gap». К ним относятся модуль UP AI Core XM 2280 с 2x Myriad-X VPU, который доступен в качестве опции для UP Squared Pro на базе Apollo Lake, UP Squared 6000 на базе Elkhart Lake и UP Xtreme x11 на базе Tiger Lake-U 11-го поколения. Теперь эти же три SBC являются первыми платами UP, предлагающими опцию для модуля ускорения искусственного интеллекта Hailo-8 M.2 от Hailo до 26 TOPS.

Hailo утверждает, что 3-TOPs на ватт Hailo-8 NPU, поставляемый с модулем M.2 за 199 долларов, значительно превосходит Edge TPU Google и Intel Movidius Myriad X по TOPS на ватт при работе приложений семантической сегментации AI и обнаружения объектов, включая ResNet50. Для развертывания Hailo-8 на UP требуется Ubuntu.
Hailo-8 доступен в растущем списке встраиваемых систем на базе Linux, совсем недавно в системе искусственного интеллекта Axiomtek RSC100 Edge на базе Arm. В большинстве других систем также используются процессоры Arm, хотя Kontron предлагает Hailo-8 пользователям Linux своей системы KBox A-150-WKL 8-го поколения на базе Whiskey Lake.
Дополнительная информация
Модели DeciNets теперь доступны для Cascade Lake со схемами ценообразования для платформ Community, Professional и Enterprise. Дополнительную информацию можно найти на странице DeciNets компании Deci.
Подробнее о Hailo-8 на плате UP можно узнать на странице Hailo-8 на UP GitHub. Опция доступна на поддерживаемых страницах покупок UP в качестве аксессуара за 199 долларов.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту linuxgizmos.com.
Оригинал статьи вы можете прочитать здесь.