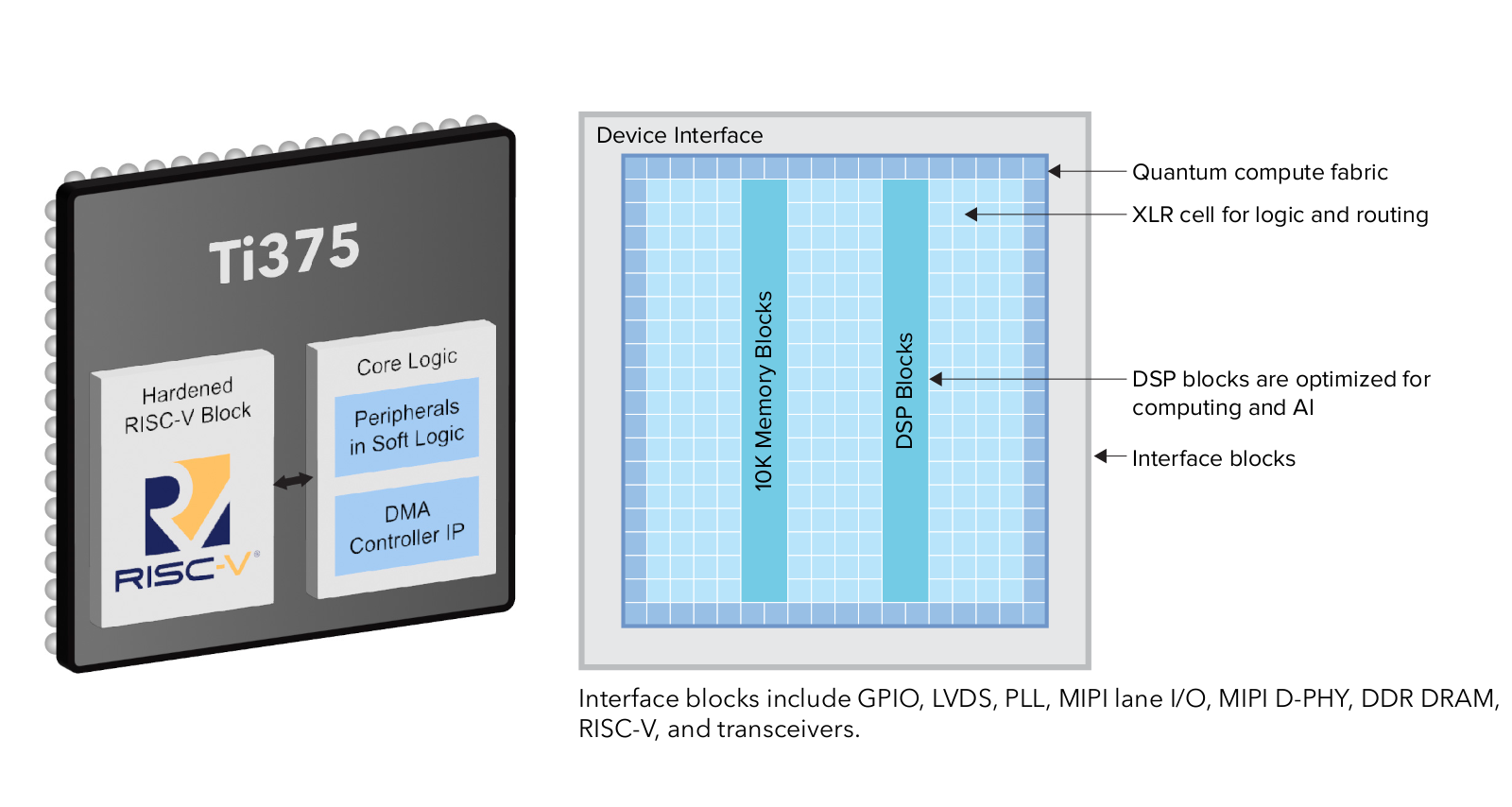
Efinix Titanium Ti375 SoC сочетает в себе технологию квантовых вычислений высокой плотности с низким энергопотреблением и четырехъядерным 32-разрядным RISC-V-блоком и оснащен контроллером LPDDR4 DRAM, MIPI D-PHY для дисплеев или камер и приемопередатчиками 16 Гбит/с, поддерживающими интерфейсы PCIe Gen 4 и 10GbE.
Читать далее «Efinix Titanium Ti375 FPGA предлагает четырехъядерный усиленный блок RISC-V, PCIe Gen 4, 10GbE»Efinix Titanium Ti375 FPGA предлагает четырехъядерный усиленный блок RISC-V, PCIe Gen 4, 10GbE