
Nvidia представила фреймворк TAO на основе графического интерфейса, который упрощает обучение модели ИИ для платформ с графическим процессором, таких как Jetson. Также в ближайшее время будет выпущен ЦП «Grace» и улучшены голосовой агент Nvidia Jarvis, Maxine video SDK и другие инструменты искусственного интеллекта.
На днях, на GTC 2021, Nvidia представила анонс, в том числе об открытии фреймворка Nvidia TAO (Train, Adapt и Optimize) для ускорения разработки ИИ. Здесь мы сосредоточимся на TAO вместе с кратким обзором улучшений голосовой технологии Nvidia Jarvis, видео SDK Maxine, видеоаналитики DeepStream и системы Merlin для глубокого обучения.
Главным событием GTC стала презентация серверно-ориентированного Grace CPU с улучшенным ИИ на базе Arm Neoverse IP следующего поколения. К 2023 году Nvidia должна была выплатить 40 миллиардов долларов за приобретение Arm.

Платформа Grace, изготовленная по технологии 7 или 5 нм, не является первым процессором Nvidia — модули Jetson основаны на процессорах Tegra на базе Arm — но, скорее всего, она станет первым процессором под брендом Nvidia, проданным третьим сторонам. Grace также может стать серьезным конкурентом чипов Intel Core и Xeon, предназначенных для предприятий.
Другие новости Nvidia включают ориентированную на сервер технологию AI-on-5G и соглашение с производителями Arm, такими как Marvell и MediaTek, о включении графических процессоров Nvidia в некоторые из своих высокопроизводительных Arm SoC. Как и TAO, все эти продукты основаны на Linux или поддерживают его.
Nvidia TAO и инструментарий Transfer Learning Toolkit
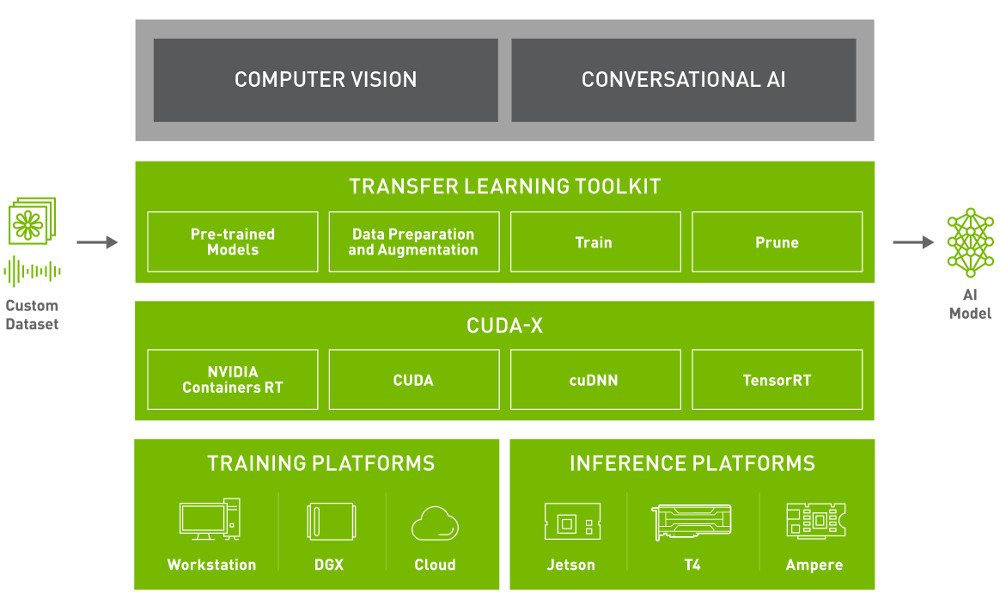
Платформа Nvidia TAO (обучение, адаптация и оптимизация) представляет собой среду на основе графического интерфейса, управляемую рабочими процессами, предназначенную для упрощения создания корпоративных приложений и сервисов искусственного интеллекта. Программное обеспечение позволяет пользователям точно настраивать предварительно обученные модели, загруженные из каталога NGC Nvidia, для речи, зрения, понимания естественного языка и многого другого.
Бесплатные модели NGC разработаны для графических процессоров Nvidia Tensor Core, которые включают графические процессоры Maxwell, Pascal и Volta, имеющиеся в модулях Jetson от Nvidia под управлением Linux. Он также поддерживает высокопроизводительные видеокарты T4 Nvidia, которые все чаще используются в периферийных системах искусственного интеллекта на базе процессоров Intel Core и даже на графических процессорах Ampere более высокого уровня.
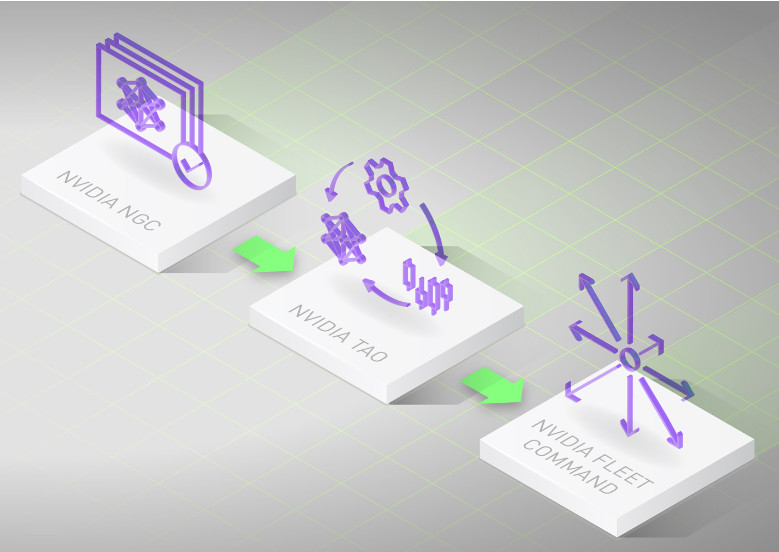
Nvidia TAO позволяет разработчикам создавать модели для конкретных предметных областей за часы, а не за месяцы, «устраняя необходимость в большом обучении и глубоких знаниях в области искусственного интеллекта», — утверждает представитель компании Nvidia. Говорят, что TAO сокращает трудоемкие задачи в рамках рабочего процесса глубокого обучения, включая подготовку данных, обучение и оптимизацию.
Nvidia TAO построена на основе инструментария Transfer Learning Toolkit (TLT), который «абстрагирует сложность инфраструктуры искусственного интеллекта и глубокого обучения и позволяет быстрее создавать предварительно обученные модели производственного качества без необходимости кодирования», — говорит представитель Nvidia. TLT использует метод, называемый трансферным обучением, который извлекает изученные функции из существующей модели нейронной сети в новую. Пользователи предоставляют небольшие наборы данных, которые TLT затем объединяет с ближайшей моделью в каталоге, чтобы конкретизировать ее.
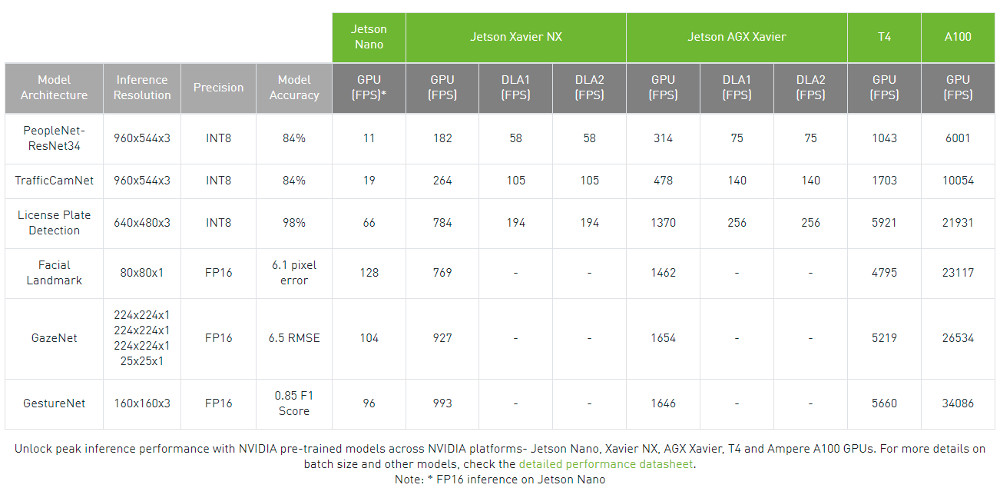
Экономия времени за счет использования предварительно обученных моделей может быть значительной. Например, модель компьютерного зрения Nvidia представляет 3700 человеко-лет, потраченных на маркировку 500 миллионов объектов из 45 миллионов кадров. Некоторые модели NGC включают учетные данные, которые удостоверяют домен, для которого модель была обучена, набор данных, который ее обучил, как часто модель развертывалась и как ожидается ее выполнение.
TAO также предоставляет объединяющую технологию обучения, позволяющую различным сайтам безопасно сотрудничать для уточнения модели, сохраняя при этом конфиденциальность наборов данных. Недавно 20 исследовательских центров использовали эту технологию для совместной работы над повышением точности модели «ЭКЗАМЕН», которая предсказывает, есть ли у пациента Covid-19. Возможности федеративного обучения расширили эту модель, позволив прогнозировать тяжесть инфекции и необходимость дополнительного кислорода.
TensorRT 8.0, Triton Inference Server 2.9 и Fleet Command
Nvidia также объявила об улучшениях нескольких технологий, которые могут быть тесно интегрированы с TAO и его TLT SDK для дальнейшей оптимизации и развертывания моделей. Например, после тонкой настройки моделей в TLT, TAO обеспечивает оптимизацию для развертывания за счет интеграции с TensorRT, SDK Nvidia для высокопроизводительного вывода данных глубокого обучения.
С помощью TensorRT вы можете гарантировать, что модель будет «эффективно работать на вашей целевой платформе, будь то массив графических процессоров на сервере или робот на базе Jetson на заводе», — говорит представитель Nvidia. TensorRT «набирает математические координаты модели» до оптимального баланса наименьшего размера с максимальной точностью для целевой системы.
Nvidia объявила о выпуске TensorRT 8.0, который, как утверждается, работает до 2 раз быстрее с точностью INT8, с точностью, аналогичной FP32. Среди других улучшений есть также оптимизация компилятора для сетей на основе трансформаторов, таких как BERT.
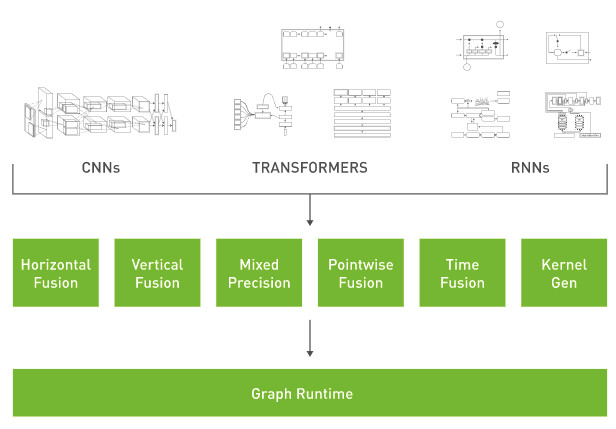

TAO также поддерживает интеграцию с сервером Triton Inference Server от Nvidia, который теперь доступен в версии 2.9. Это программное обеспечение с открытым исходным кодом для обслуживания логических выводов оптимизирует модель для развертывания на оптимальной платформе. Оптимизация основана на вводе пользователем оптимальной конфигурации развертывания модели, архитектуры и другой информации.
Новые функции Triton 2.9 включают в себя инструмент Model Navigator на альфа-стадии, который преобразует модели TensorFlow и PyTorch в TensorRT, а также бета-поддержку для внутреннего интерфейса Intel OpenVINO. Инструмент Model Analyzer теперь автоматически определяет оптимальный размер пакета и количество параллельных экземпляров модели.
После выбора платформы TAO позволяет пользователям запускать Nvidia Fleet Command для развертывания и управления AI-приложением на различных устройствах с графическим процессором. Fleet Command работает с серверами, сертифицированными Nvidia, через интерфейс браузера, чтобы «безопасно сопрягать, организовывать и управлять миллионами серверов, развертывать искусственный интеллект в любом удаленном месте и обновлять программное обеспечение по мере необходимости», — говорит представитель Nvidia.
Nvidia Jarvis
В конце февраля вышла бета-версия 1.0 голосовой платформы Nvidia Jarvis, которая будет доступна для публичной загрузки в конце этого квартала. Новый выпуск предоставляет возможности «говорящего» ИИ, включая «высокоточное автоматическое распознавание речи, перевод в реальном времени на несколько языков и возможности преобразования текста в речь для создания выразительных «говорящих» ИИ-ассистентов», — говорит представитель Nvidia.
По заявлению Nvidia, нестандартная модель распознавания речи Jarvis 1.0 теперь обеспечивает точность более 90%. Модель можно настроить с помощью TLT TAO. Возможность перевода в реальном времени поддерживает пять языков и может выполняться перевод с задержкой менее 100 мс на предложение.
Nvidia Maxine, AI Face Codec и DeepStream 6.0
Ранее представленный Nvidia Maxine SDK для приложений виртуального сотрудничества и создания контента теперь доступен для загрузки. Разработанный для таких приложений, как видеоконференцсвязь и потоковое вещание, Maxine может интегрироваться с голосовыми функциями Jarvis.
Maxine SDK на базе графического процессора включает в себя SDK видеоэффектов для сверхвысокого разрешения, удаления видеошумов и виртуального фона. SDK дополненной реальности обеспечивает 3D-эффекты, такие как отслеживание лица и оценка позы тела. Также существует SDK Audio Effects, который обеспечивает высококачественное удаление шума и эха помещения.
В новостях по теме разработки Nvidia анонсировала кодек AI Face Codec, который сжимает видео и отображает человеческие лица для видеоконференций. По заявлению Nvidia, кодек AI Face Codec может обеспечить сокращение пропускной способности до 10 раз по сравнению с H.264.
В то время как Maxine помогает создавать совместные видеоприложения, Nvidia DeepStream SDK помогает анализировать видео с помощью потоковой аналитики. Nvidia анонсировала DeepStream 6.0, который добавляет графический интерфейс и оптимизирует рабочий процесс «от прототипирования до развертывания на периферии и в облаке».
Nvidia Merlin
Теперь доступна последняя открытая бета-версия платформы приложений Nvidia Merlin для рекомендательных систем глубокого обучения. Релиз упрощает определение рабочих процессов и конвейеров обучения и улучшает поддержку вывода и интеграции с Triton Inference Server. Другие улучшения включают возможность прозрачного масштабирования для более крупных наборов данных и более сложных моделей.
Дополнительная информация
Основные части Nvidia TAO, включая инструментарий Transfer Learning Toolkit и федеративное обучение, уже доступны. Дополнительную информацию и форму заявки на ранний доступ можно найти на странице продукта Nvidia TAO.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту linuxgizmos.com
Оригинал статьи вы можете прочитать здесь.