
CNXSoft: Это пост от гостя — Грега Литла, вице-президента по инжинирингу, Au-Zone Technologies . Au-Zone Technologies является частью партнерской сети Toradex.
Обнаружение и классификация объектов на маломощном Arm SoC
Методы машинного обучения оказались очень эффективными для решения широкого круга задач по обработке изображений и их классификации. Хотя многие встроенные системы IoT, развернутые на сегодняшний день, используют подключенные облачные ресурсы для машинного обучения, наблюдается растущая тенденция к внедрению этой обработки на конечном устройстве. Выбор соответствующих системных компонентов и инструментов для реализации этой обработки изображений на конечном устройстве снижает трудоемкость, время и риск этих конструкций. Это иллюстрируется на примере реализации, которая обнаруживает и классифицирует различные типы макарон на движущейся конвейерной ленте.
Пример использования
Для этого примера мы рассмотрим проблему обнаружения и классификации различных объектов на конвейерной ленте. Мы выбрали макаронные изделия в качестве примера, но эту общую технику можно применить к большинству других объектов.

Аппаратная архитектура
Существует широкий спектр встроенных процессоров Arm, подходящих для обработки встроенных изображений с различной мощностью, производительностью и стоимостью. Выбор семейства процессоров или модулей с набором совместимых компонентов обеспечивает гибкость масштабирования конструкции при изменении требований к обработке в течение срока службы конструкции или продукта. Вывод машинного обучения в режиме реального времени является вычислительно-интенсивным процессом, который часто может быть реализован более эффективно на встроенных графических процессорах или сопроцессорах из-за параллельного характера базовых тензорных математических операций, поэтому предпочтительным является встроенный SoC с одним из этих вычислительных ресурсов. Еще один довод — это периферийные интерфейсы и диапазон вычислений, необходимый для баланса системы. К счастью, есть ряд процессоров SoC, доступных от ряда поставщиков кремния, которые поддерживают эти функции.
В этом примере был выбран компьютер Toradex Apalis на модуле на базе процессора серии NXP i.MX 8. Этот модуль доступен с 2x Arm Cortex-A72, 4X Cortex-A53, 2x Arm Cortex-M4F, 2x встроенными графическими процессорами и встроенным аппаратным видео-кодеком. Этот модуль является отличным выбором для промышленного применения с более чем 10-летним сроком службы и поддержкой промышленного температурного диапазона. Linux, предоставляемый Toradex позволяет нам сосредоточиться на приложении.

Выбор подходящего датчика изображения и процессора датчика изображения (ISP) для предполагаемого применения имеет решающее значение для успешной реализации. Такие требования, как разрешение, чувствительность, динамический диапазон и интерфейс, являются важными факторами, которые необходимо учитывать. Если объект находится в значительном движении по отношению к частоте кадров, то следует учитывать общий датчик изображения, чтобы избежать искажения в захваченных изображениях.
Метод интерфейса датчика изображения также является важным фактором. Интерфейсы, такие как USB или Gigabit Ethernet, которые обычно используются для создания образов на ПК, имеют дополнительные затраты, мощность и производительность по сравнению с MIPI CSI или параллельными интерфейсами, которые поддерживаются в Toradex Apalis COM.
Для захвата изображения был выбран модуль встроенной камеры Allied Vision Alvium с датчиком ON-Semi MT9P031. Этот модуль камеры использует последовательный интерфейс MIPI CSI-2 и содержит ISP для предварительной обработки необработанных данных датчика для оптимального качества изображения. Интернет-провайдер также разгружает встроенный процессор от таких операций, как коррекция битых пикселей, управление экспозицией и удаление массива цветовых фильтров. Модули Alvium также являются хорошим выбором для промышленного/коммерческого продукта из-за длительной доступности, диапазона поддерживаемых датчиков изображения и качества класса машинного зрения.

Архитектура программного обеспечения
Теперь, когда аппаратные компоненты были выбраны, необходимо рассмотреть варианты проектирования и реализации обработки изображений для задач высокого уровня, показанных на рисунке 4.
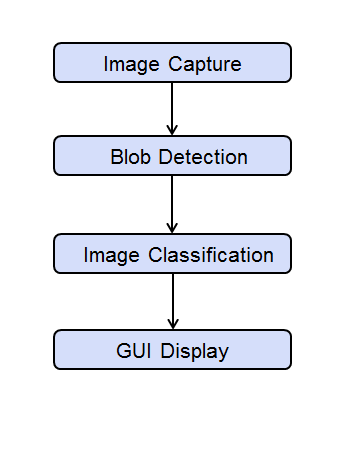
Драйвер Video4Linux2 (V4L2) доступен для модуля Alvium Camera, что упрощает интеграцию с BSP Toradex i.mx8QM Linux. Затем должен быть реализован детектор BLOB-объектов, чтобы найти несколько областей интереса в захваченном изображении для каждого идентифицируемого объекта. Как только области интереса определены, они могут быть переданы в качестве входных данных для механизма логического вывода нейронной сети для классификации. Наконец, результаты классификации используются для маркировки исходного изображения для отображения на дисплее графического интерфейса.
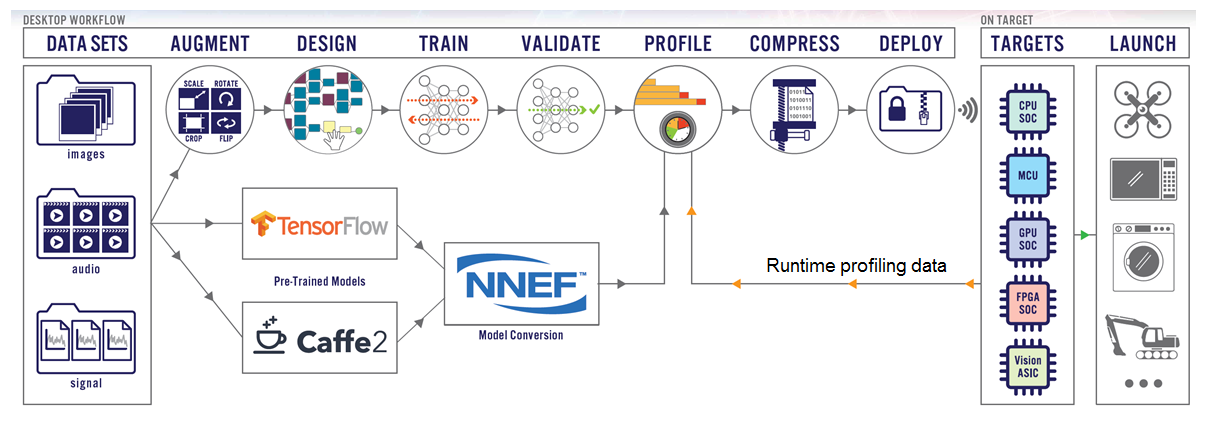
Au-Zone DeepView Toolkit был использован для реализации классификатора изображений на основе машинного обучения. DeepView поддерживает процесс проектирования, показанный на рисунке 5, а также встроенный код механизма вывода времени выполнения, который выполняется на целевой платформе.
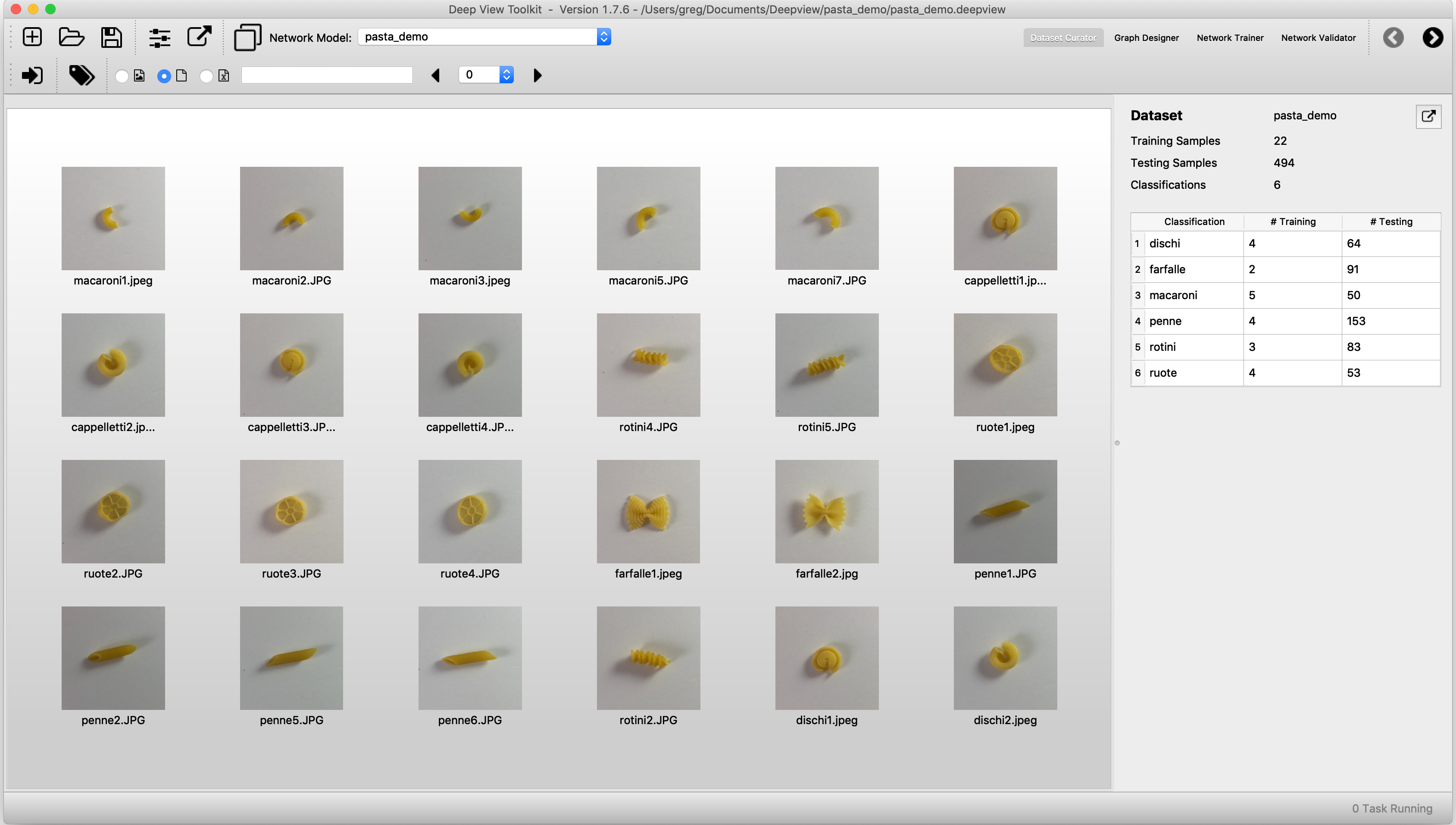
Тренировочные образы
Для этого примера использовались шесть различных типов макарон. Четыре обучающих изображения каждого типа пасты были сняты с помощью iPhone на случайных образцах, независимых от тестовых образцов.
Инструмент DeepView импортирует небольшие обучающие образцы и выполняет Transfer learning модели MobileNet с использованием Tensorflow backend. В этом случае Transfer learning Training завершено на настольном ПК с точностью до 98% примерно за 30 секунд. Дополнительная проверка окончательного решения выполняется для подтверждения окончательной точности с помощью встроенной камеры, поскольку для обучения было снято ограниченное количество изображений.
Преобразование модели TensorFlow в модель DeepViewRT run-time для выполнения на встроенном процессоре или графическом процессоре.

Программное обеспечение процесса подготовки изображения
Процесс подготовки изображения для демонстрации представлен ниже на рисунке 9. После захвата изображения аппаратный механизм G2D использовался для изменения размера изображения в соответствии с требуемым разрешением и интересующей областью. Затем сервер DeepView Camera Server разделил видео на текстуру OpenGL для отображения в графическом интерфейсе на основе Qt и кадры для детектора BLOB, который был реализован с использованием DLIB с использованием традиционных методов обработки изображений. Это подходит для простой задачи обнаружения объекта на фиксированном фоне. Для более сложных задач в CNN будет реализован Single Shot MultiBox Detector (SSD), однако это будет иметь значительно более высокую нагрузку.
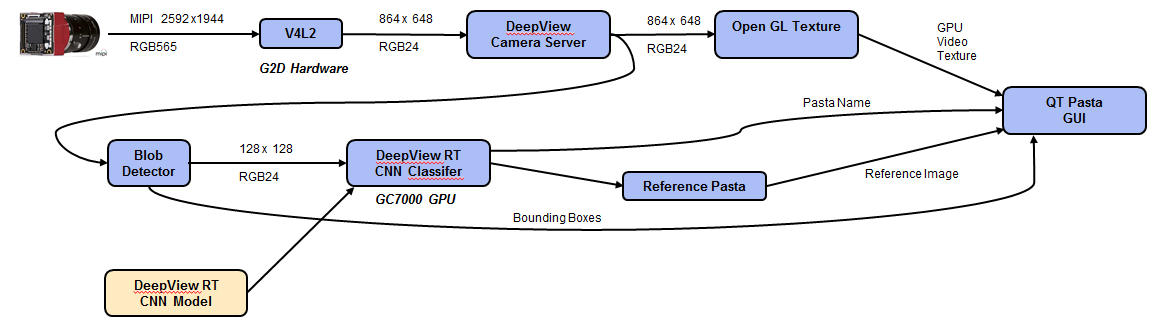
Детектор BLOB-объектов создает области, ограниченные прямоугольником, представляющие интерес для классификатора DeepView, а также для отображения графического интерфейса.

Наконец, в графическом интерфейсе отображаются макароны с подписью и оригинальными изображениями для справки.

Производительность
DeepViewRT run-time engine поддерживает классификатор CNN, работающий на встроенном графическом процессоре GC7000, в балансе с приложениями, работающими на ядрах процессора. Скорость вывода, для данного примера, для Mobilenet V2_0.35_128 находится в диапазоне 36 результатов в секунду. Загрузка ЦП зависит от скорости подготовки изображения, так как это влияет на алгоритм детектора. Текущая загрузка ЦП для всего приложения находится в диапазоне от 15 до 25%, что оставляет дополнительные затраты на более сложный вариант использования или реализацию на совместимом COM-модуле i.MX 8 с более низкой стоимостью и производительностью.
Дальнейшая оптимизация
Дополнительная оптимизация подготовки изображений для полного использования DMA еще больше снизит нагрузку на процессор, это не было доступно в предварительной версии BSP, но ожидается, что будет поддерживаться в будущих выпусках. Разрешение сохраняемых кадров из модуля камеры также может быть значительно уменьшено для этого простого приложения с будущими обновлениями драйверов.
Заключение
Машинное обучение является мощным инструментом для обработки изображений на конечных устройствах. С помощью выбора доступных инструментов и компонентов можно быстро спроектировать и внедрить недорогой, маломощный детектор объектов и классификатор во встроенный продукт, который использует как процессорную, так и графическую обработку для оптимальной производительности.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту cnx-software.com.
Оригинал статьи вы можете прочитать здесь.