
Мы наблюдаем массовую нехватку ресурсов для встраиваемых устройств из-за отсутствия зрелых программных стеков. С увеличением количества оборудования с открытым исходным кодом доступная программная поддержка требует значительного времени для разработки приложений AI/ML/DL. Некоторые из проблем, с которыми сегодня приходится сталкиваться, заключаются в том, что в Bare Metal-устройствах отсутствует управление памятью на устройстве и поддержка LLVM. Их также сложно отлаживать из-за жесткого программирования и интерфейсов кросс-компиляции.
Из-за этого «сегодня сложно оптимизировать и развернуть рабочие нагрузки машинного обучения на Bare Metal — устройствах». Для решения этих проблем разработана поддержка TVM, платформы компилятора машинного обучения с открытым исходным кодом для ЦП, графических процессоров и ускорителей машинного обучения, на этих устройствах без операционной системы, а Apache TVM использует основу с открытым исходным кодом. «ΜTVM — это компонент TVM, который обеспечивает широкую поддержку инфраструктуры, мощное промежуточное программное обеспечение компилятора и гибкие возможности автонастройки и компиляции для встраиваемых платформ».
TVM, имеющий внутреннюю часть микроконтроллера, называется uTVM (MicroTVM), который упрощает выполнение тензорных программ на Bare Metal- устройствах, которые, в свою очередь, обеспечивают автоматическую оптимизацию через AutoTVM. Это, в частности, предоставляет альтернативу TensorFlow Lite для микроконтроллеров.

Как работают uTVM и AutoTVM?
В одном из примеров, продемонстрированных OctoML, используется плата STM32F746ZG, подключенная к настольному компьютеру через порт USB-JTAG. Главный компьютер работает под управлением OpenOCD, который разрешает JTAG-соединения, а затем позволяет uTVM управлять SoC на плате, используя не зависящий от устройства TCP-сокет.
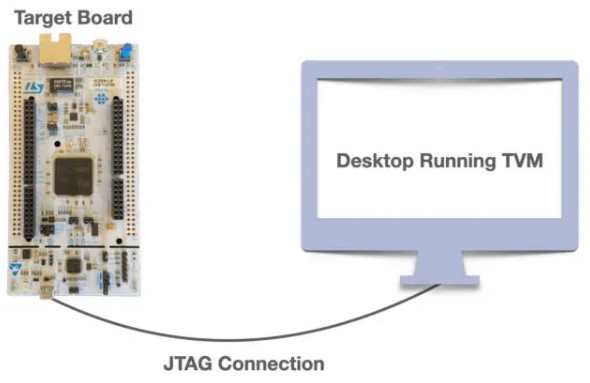
Более подробную информацию можно найти на веб-сайте Apache TVM. Производительность по сравнению с оптимизированной вручную библиотекой ядер машинного обучения кажется почти такой же, как у CMSIS-NN.
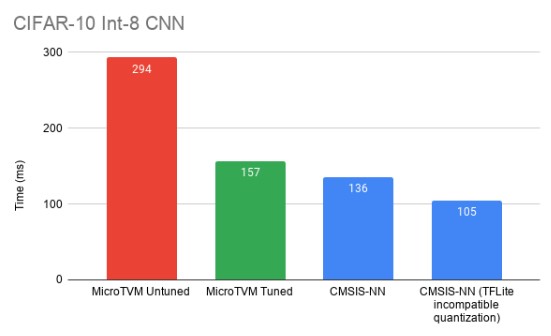

Но среда выполнения по-прежнему является проблемой, поскольку она пока не подходит для развертывания модели, которая в значительной степени зависит от хост-машины. Итак, AutoTVM запускает модель на целевом сервере со случайными входными данными.
«Ленивое выполнение позволяет нам запускать один и тот же оператор много раз, не возвращая управление хосту, поэтому затраты на связь амортизируются при каждом запуске, и мы можем лучше понять профиль производительности». Для этого необходимо использовать как флэш-память, так и оперативную память.
Согласно OctoML, «MicroTVM для одноядерной оптимизации уже готов и является выбором для этого варианта использования. Поскольку теперь мы создаем поддержку автономного развертывания, мы надеемся, что вы так же взволнованы, как и мы, тем, чтобы сделать µTVM выбором и для развертывания модели. Однако это не просто зрелищный вид спорта — помните: все это с открытым исходным кодом! µTVM все еще находится на начальной стадии, поэтому каждый человек может иметь большое влияние на его развитие. Ознакомьтесь с руководством для авторов TVM, если вы заинтересованы в сотрудничестве с нами, или переходите прямо на форумы TVM, чтобы обсудить идеи».
Было несколько разговоров о uTVM для Bare Metal-устройств.
Выражаем свою благодарность источнику из которого взята и переведена статья, сайту cnx-software.com.
Оригинал статьи вы можете прочитать здесь.