
В Ubuntu 16.04 и многих других, недавних операционных системах до сих пор используют одно поточный вариант сжатия данных & файлов, с помощью утилит bzip2 или gzip по умолчанию, но некоторое время назад появились новые инструменты совместимые с много поточным сжатием, такие как lbzip2, pigz или pixz, теперь вы можете заменить инструменты используемые по умолчания, для получения более быстрого сжатия и распаковки на много-ядерных системах. В этой статье пойдет обсуждение алгоритма сжатия Facebook’s Z-стандарт 1.0, обещающего более быстрое и качественное сжатие. Проект имеет как открытый исходный код, он выпущен под BSD лицензией и предлагает, как одно поточный инструмент zstd, так и много-поточный инструмент pzstd. Так что многие уже начали делать собственные небольшие тесты, результаты были поразительны. Некоторые опасения вызывают патенты, но пока разработчики продолжают работу над выявлением и исправлением ошибок включающих в себя pzstd segfaulting на ARM.
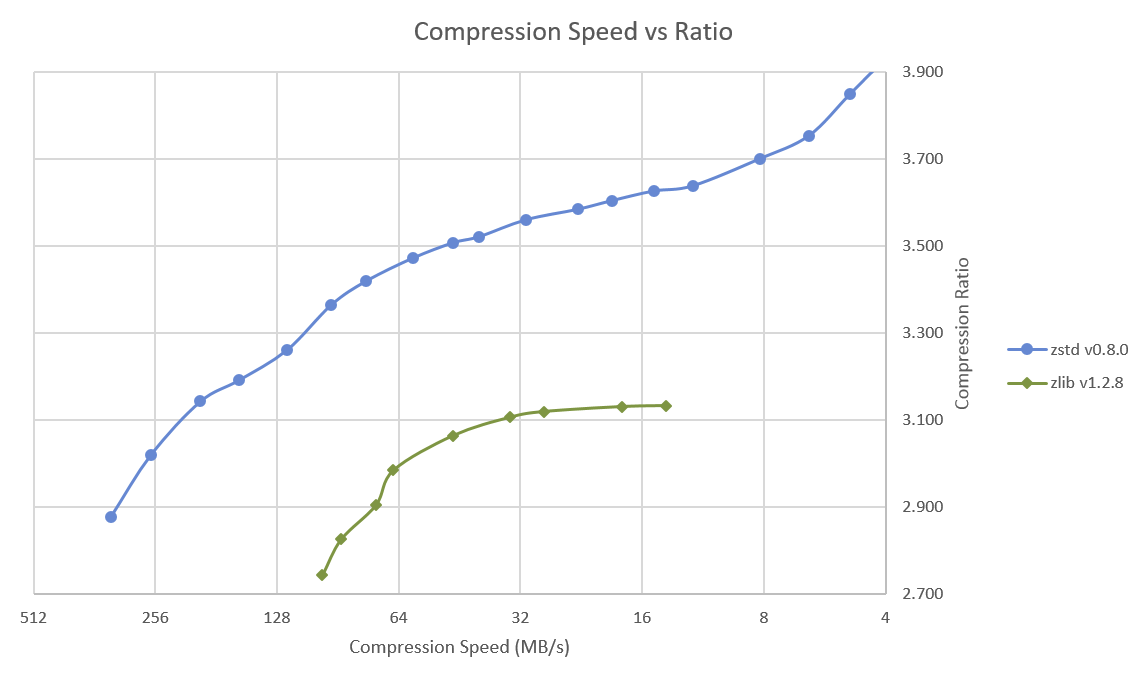
Zlib имеет 9 уровень сжатия, в то время как Zstd имеет 19, Facebook протестировал все уровни сжатия и скорость, и нарисовал диаграмму, показанную выше, сравнения скорости сжатия и коэффициент сжатия и Zstd явно превосходит zlib.
Они также сравнили производительность и коэффициент сжатия, и распаковки для различных других, конкурирующих, быстрых алгоритмов используя lzbench, для выполнения тестирования из памяти, во избежании ввода/вывода данных из устройств хранения.
| Имя | Степень сжатия | C.speed | D.speed |
|---|---|---|---|
| MB/s | MB/s | ||
| zstd 1.0.0 -1 | 2.877 | 330 | 940 |
| zlib 1.2.8 -1 | 2.730 | 95 | 360 |
| brotli 0.4 -0 | 2.708 | 320 | 375 |
| QuickLZ 1.5 | 2.237 | 510 | 605 |
| LZO 2.09 | 2.106 | 610 | 870 |
| LZ4 r131 | 2.101 | 620 | 3100 |
| Snappy 1.1.3 | 2.091 | 480 | 1600 |
| LZF 3.6 | 2.077 | 375 | 790 |
Среди всех этих алгоритмов Zstd имеет самую большую скорость и самый высокий коэффициент сжатия.
Но давайте вместо того чтобы просто доверять Facebook протестируем его самостоятельно. Последняя представленная версия 1.1.2, вот таким образом можно установить ее в Ubuntu 16.04:
wget https://github.com/facebook/zstd/archive/v1.1.2.tar.gz tar xf v1.1.2.tar.gz cd zstd-1.1.2/ make sudo make install
Таким образом была установлена последняя, стабильная версия zstd, но в нее по умолчанию не входит поддержка много-поточного режима:
make -C contrib/pzstd/ sudo cp contrib/pzstd/pzstd /usr/local/bin/
В zstd есть довольно таки много настроек:
zstd -h *** zstd command line interface 64-bits v1.1.2, by Yann Collet *** Usage : zstd [args] [FILE(s)] [-o file] FILE : a filename with no FILE, or when FILE is - , read standard input Arguments : -# : # compression level (1-19, default:3) -d : decompression -D file: use `file` as Dictionary -o file: result stored into `file` (only if 1 input file) -f : overwrite output without prompting --rm : remove source file(s) after successful de/compression -k : preserve source file(s) (default) -h/-H : display help/long help and exit Advanced arguments : -V : display Version number and exit -v : verbose mode; specify multiple times to increase log level (default:2) -q : suppress warnings; specify twice to suppress errors too -c : force write to standard output, even if it is the console -r : operate recursively on directories --ultra : enable levels beyond 19, up to 22 (requires more memory) --no-dictID : don't write dictID into header (dictionary compression) --[no-]check : integrity check (default:enabled) --test : test compressed file integrity --[no-]sparse : sparse mode (default:enabled on file, disabled on stdout) -M# : Set a memory usage limit for decompression -- : All arguments after "--" are treated as files Dictionary builder : --train ## : create a dictionary from a training set of files -o file : `file` is dictionary name (default: dictionary) --maxdict ## : limit dictionary to specified size (default : 112640) -s# : dictionary selectivity level (default: 9) --dictID ## : force dictionary ID to specified value (default: random) Benchmark arguments : -b# : benchmark file(s), using # compression level (default : 1) -e# : test all compression levels from -bX to # (default: 1) -i# : minimum evaluation time in seconds (default : 3s) -B# : cut file into independent blocks of size # (default: no block)
Так как мы будем сравнивать результаты с другими алгоритмами, кэш файл отчищался перед каждым тестированием сжатия и распаковки:
sync sudo echo 3 | sudo tee /proc/sys/vm/drop_caches
Сжатие, с использованием настроек по умолчанию, основных каталогов Linux находящихся на жестком диске, с помощью tar + zstd (одиночный потокц):
time tar -I zstd -cf linux3.tar.zst linux real 2m10.056s user 1m31.608s sys 0m15.220s
и pzstd (множество потоков):
time tar -I pzstd -cf linux4.tar.zst linux real 0m58.929s user 1m26.560s sys 0m15.464
Имейте ввиду, что небольшую задержку вызывает ввод/вывод данных на стороне жесткого диска и если вы хотите сравнивать конкретно производительность компрессора вам необходимо использовать lzbench. Теперь давайте распакуем архив с помощью Z-стандарта:
mkdir linux3 linux4 time tar -I zstd -xf linux3.tar.zst -C linux3 real 0m45.124s user 0m21.260s sys 0m9.340s time tar -I zstd -xf linux4.tar.zst -C linux4 real 0m38.715s user 0m23.392s sys 0m11.496s
Ниже приведена таблица сравнения времени распаковки и сжатия, на компьютере с восьмиядерным процессором AMD FX8350 и результаты пользовательского тестирования.
| Сжатие | Распаковка | Размер файла (байт) | Степень сжатия | |||
| Инструменты | Время (с) | “Пользовательское” Время (с) | Время (с) | “Пользовательское” Время (с) | ||
| ztsd | 130.056 | 91.608 | 45.124 | 21.26 | 1,881,020,744 | 1.48 |
| pzstd | 58.929 | 86.56 | 38.175 | 23.39 | 1,883,697,296 | 1.48 |
| lbzip2 | 84.216 | 353.84 | 37.109 | 167.416 | 1,855,837,345 | 1.50 |
| pigz | 61.121 | 121.332 | 34.36 | 15.26 | 1,903,915,372 | 1.47 |
| pixz | 177.596 | 1233.88 | 36.24 | 78.116 | 1,782,756,524 | 1.57 |
| pzstd -19 | 275.361 | 1939.536 | 26.85 | 21.832 | 1,794,035,552 | 1.56 |
I’ve included both “real time” and “user time”, as the latter shows how much CPU time the task has spent on all the cores of the system. Если «пользовательское» время больше это означает что задача требует большей мощности процессора, но если «пользовательское» время ниже это значит, что инструмент более эффективен и требует меньше мощности. pigz это много-поточная версия алгоритма xz опирающаяся на lzma сжатие, которое обеспечивает более высокую степень сжатия, за счет более длительного времени сжатия, так что следующим шагом проверим pzstd с 19 уровнем сжатия для сравнения:
time tar -I "pzstd -19" -cf linux7.tar.zst linux real 4m35.361s user 32m19.536s sys 0m18.500s
Степень сжатия Z-стандарта очень похожа на один из lbzip2 с настройками по умолчанию, но сжатие более быстрое и энерго-эффективное. По сравнению с gzip, (p)zstd предлагает лучшую степень сжатия, при работе с настройками по умолчанию и сопоставимой производительностью. pixz предлагает лучшую степень сжатия, но занимает больше времени на сжатие и использует больше ресурсов при распаковке, по сравнению с Z-стандартом и Pigz. Pzstd обладая 19 уровнем сжатия использует еще больше времени, его основным преимуществом является более быстрая скорость распаковки.
Выражаем свою благодарность источнику с которого взята и переведена статья, сайту cnx-software.com.
Оригинал статьи вы можете прочитать здесь.